
Microsoft’s new generative AI model is leaner and more capable than even bigger language models.
Microsoft‘s new generative AI model
In the world of large language models (LLM) like GPT-4 and Bard, Microsoft has just released a new small language model—Phi-2, which has 2.7 billion parameters and is an upgraded version of Phi-1.5. Currently available via the Azure AI Studio model catalogue, Microsoft claims that Phi-2 can outperform larger models such as Llama-2, Mistral, and Gemini-2 in various generative AI benchmark tests.
Originally announced by Satya Nadella at Ignite 2023 and released earlier this week, Phi-2 was built by the Microsoft research team, and the generative AI model is said to have “common sense,” “language understanding,” and “logical reasoning.” According to the company, Phi-2 can even outperform models that are 25 times larger on specific tasks.
Microsoft Phi-2 SLM is trained using “textbook-quality” data, which includes synthetic datasets, general knowledge, theory of mind, daily activities, and more. It is a transformer-based model with capabilities like a next-word prediction objective. Microsoft has trained Phi-2 on 96 A100 GPUs for 14 days, indicating that it is easier and more cost-effective to train this model on specific data compared to GPT-4. GPT-4 is reported to take around 90-100 days for training, using tens of thousands of A100 Tensor Core GPUs.
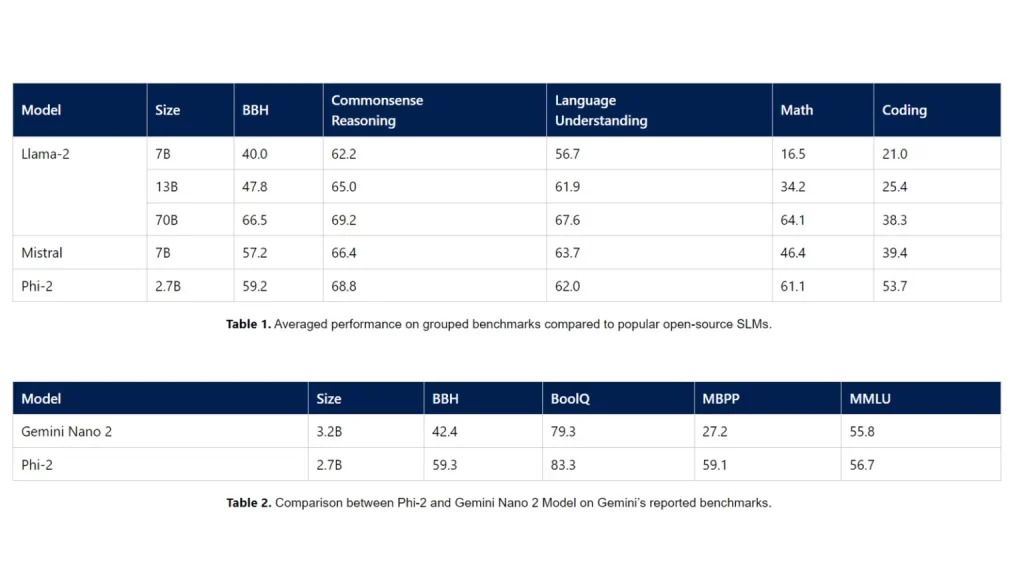
On benchmarks like commonsense reasoning, language understanding, math, and coding, Phi-2 outperforms the 13B Llama-2 and 7B Mistral. Similarly, the model also outperforms the 70B Llama-2 LLM by a significant margin. Not just that, it even outperforms the Google Gemini Nano 2, a 3.25B model, which can natively run on Google Pixel 8 Pro.